RR-GCN
RandomRGCNConv
- class rrgcn.random_rgcn_conv.RandomRGCNConv(in_channels: int | Tuple[int, int], out_channels: int, num_relations: int, seed: int | None = None, **kwargs)[source]
Bases:
MessagePassingRandom graph convolution operation, characterized by a single seed.
- Args:
- in_channels (int or tuple):
Size of each input sample. A tuple corresponds to the sizes of source and target dimensionalities. In case no input features are given, this argument should correspond to the number of nodes in your graph.
- out_channels (int):
Size of each output sample.
- num_relations (int):
Number of relations.
- seed (int):
Random seed (fully characterizes the layer).
- **kwargs (optional):
Additional arguments of
torch_geometric.nn.conv.MessagePassing.
- forward(x: Tensor | None | Tuple[Tensor | None, Tensor], edge_index: Tensor | SparseTensor, edge_type: Tensor | None = None)[source]
- Args:
- x:
The input node features. Can be either a
[num_nodes, in_channels]node feature matrix, or an optional one-dimensional node index tensor (in which case input features are treated as trainable node embeddings). Furthermore,xcan be of typetupledenoting source and destination node features.- edge_index (LongTensor or SparseTensor):
The edge indices.
- edge_type:
The one-dimensional relation type/index for each edge in
edge_index. Should be onlyNonein caseedge_indexis of typetorch_sparse.tensor.SparseTensor. (default:None)
- message(x_j: Tensor) Tensor[source]
Constructs messages from node
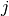 to node
to node 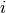 in analogy to
in analogy to 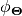 for each edge in
for each edge in
edge_index. This function can take any argument as input which was initially passed topropagate(). Furthermore, tensors passed topropagate()can be mapped to the respective nodes and by appending _ior_jto the variable name, .e.g.x_iandx_j.
- message_and_aggregate(adj_t: SparseTensor, x: Tensor) Tensor[source]
Fuses computations of
message()andaggregate()into a single function. If applicable, this saves both time and memory since messages do not explicitly need to be materialized. This function will only gets called in case it is implemented and propagation takes place based on atorch_sparse.SparseTensoror atorch.sparse.Tensor.
RRGCNEmbedder
- class rrgcn.random_rgcn_embedder.RRGCNEmbedder(num_nodes: int, num_layers: int, num_relations: int, emb_size: int, device: device | str = 'cuda', ppv: bool = True, seed: int = 42, min_node_degree: int = 0)[source]
Bases:
ModuleRandom Relational Graph Convolutional Network Knowledge Graph Embedder.
- Args:
- num_nodes (int):
Number of nodes in the KG.
- num_layers (int):
Number of random graph convolutions.
- num_relations (int):
Number of relations in the KG.
- emb_size (int):
Desired embedding width.
- device (torch.device or str, optional):
PyTorch device to calculate embeddings on. Defaults to “cuda”.
- ppv (bool, optional):
If True, concatenate PPV features to embeddings (this effectively doubles the embedding width). Defaults to True.
- seed (int, optional):
Seed used to generate random transformations (fully characterizes the embedder). Defaults to 42.
- min_node_degree (int, optional):
If set, embedder first remove all nodes with a degree lower than the given argument from the graph before taking subgraph. Defaults to 0.
- embeddings(edge_index: Tensor | SparseTensor, edge_type: Tensor | None = None, batch_size: int = 0, node_features: Dict[int, Tuple[Tensor, Tensor]] | None = None, node_features_scalers: Dict[int, TransformerMixin] | str | None = 'standard', idx: Tensor | None = None, subgraph: bool = True) Tensor[source]
Generate embeddings for a given set of nodes of interest.
- Args:
- edge_index (torch.Tensor or torch_sparse.SparseTensor):
Adjacency matrix. Either in 2-row head/tail format or using a SparseTensor.
- edge_type (torch.Tensor, optional):
Types for each edge in edge_index. Can be omitted if edge_index is a SparseTensor where types are included as values. Defaults to None.
- batch_size (int, optional):
Number of nodes in a single batch. For every batch, a subgraph with number of hops equal to the number of graph convolutions around the included nodes is extracted and used for message passing. If batch_size is 0, all nodes of interest are contained in a single batch. Defaults to 0.
- node_features (Dict[int, Tuple[torch.Tensor, torch.Tensor]], optional):
Dictionary with featured node type identifiers as keys, and tuples of node indices and initial features as values.
For example, if nodes [3, 5, 7] are literals of type 5 with numeric values [0.7, 0.1, 0.5], node_features should be: {5: (torch.tensor([3, 5, 7]), torch.tensor([0.7], [0.1], [0.5]))}
Featured nodes are not limited to numeric literals, e.g. word embeddings can also be passed for string literals.
The node indices used to specify the locations of literal nodes should be included in idx (if supplied).
- node_features_scalers (Dict[int, TransformerMixin] or str, optional):
Dictionary with featured node type identifiers as keys, and sklearn scalers as values. If scalers are not fit, they will be fit on the data. The fit scalers can be retrieved using .get_last_fit_scalers(). Can also be “standard”, “robust”, “power”, “quantile” as shorthands for an unfitted StandardScaler, RobustScaler, PowerTransformer and QuantileTransformer respectively. If None, no scaling is applied. Defaults to “standard”.
- idx (torch.Tensor, optional):
Node indices to extract embeddings for (e.g. indices for train- and test entities). If None, extracts embeddings for all nodes in the graph. Defaults to None.
- subgraph (bool, optional):
If False, the function does not take a k-hop subgraph before executing message passing. This is useful for small graphs where embeddings can be extracted full-batch and calculating the subgraph comes with a significant overhead. Defaults to True.
- Returns:
torch.Tensor: Node embeddings for given nodes of interest
- estimated_peak_memory_usage(edge_index: Tensor | SparseTensor, batch_size: int = 0, idx: Tensor | None = None, subgraph: bool = True, **kwargs)[source]
Calculates the theoretical peak memory usage for a set of arguments given to RRGCNEmbedder.embeddings()
- Args:
- edge_index (torch.Tensor or torch_sparse.SparseTensor):
Adjacency matrix. Either in 2-row head/tail format or using a SparseTensor.
- edge_type (torch.Tensor, optional):
Types for each edge in edge_index. Can be omitted if edge_index is a SparseTensor where types are included as values. Defaults to None.
- batch_size (int, optional):
Number of nodes in a single batch. For every batch, a subgraph with number of hops equal to the number of graph convolutions around the included nodes is extracted and used for message passing. If batch_size is 0, all nodes of interest are contained in a single batch. Defaults to 0.
- idx (torch.Tensor, optional):
Node indices to extract embeddings for (e.g. indices for train- and test entities). If None, extracts embeddings for all nodes in the graph. Defaults to None.
- subgraph (bool, optional):
If False, the function does not take a k-hop subgraph before executing message passing. This is useful for small graphs where embeddings can be extracted full-batch and calculating the subgraph comes with a significant overhead. Defaults to True.
- Returns:
int: Theoretical peak memory usage in number of bytes
- forward(edge_index: Tensor | SparseTensor, edge_type: Tensor | None = None, node_features: Dict[int, Tuple[Tensor, Tensor]] | None = None, node_idx: Tensor | None = None) Tensor[source]
Calculates node embeddings for a (sub)graph specified by a typed adjacency matrix
- Args:
- edge_index (torch.Tensor or torch_sparse.SparseTensor):
Adjacency matrix. Either in 2-row head/tail format or using a SparseTensor.
- edge_type (torch.Tensor, optional):
Types for each edge in edge_index. Can be omitted if edge_index is a SparseTensor where types are included as values. Defaults to None.
- node_features (Dict[int, Tuple[torch.Tensor, torch.Tensor]], optional):
Dictionary with featured node type identifiers as keys, and tuples of node indices and initial features as values.
For example, if nodes [3, 5, 7] are literals of type 5 with numeric values [0.7, 0.1, 0.5], node_features should be: {5: (torch.tensor([3, 5, 7]), torch.tensor([0.7], [0.1], [0.5]))}
Featured nodes are not limited to numeric literals, e.g. word embeddings can also be passed for string literals.
The node indices used to specify the locations of literal nodes should be included in node_idx (if supplied).
- node_idx (torch.Tensor, optional):
Useful for batched embedding calculation. Mapping from node indices used in the given (sub)graph’s adjancency matrix to node indices in the original graph. Defaults to None.
- Returns:
torch.Tensor: Node embeddings for given (sub)graph.
NodeEncoder
- class rrgcn.node_encoder.NodeEncoder(emb_size: int, num_nodes: int, seed: int = 42, device: device | str = 'cuda')[source]
Bases:
ModuleRandom (untrained) node encoder for the initial node embeddings, supports initial feature vectors (i.e. literal values, e.g. floats or sentence/word embeddings).
The encoder supports nodes of different types, that each have different associated feature vectors. Every different “featured” node type should have an associated integer identifier.
- Args:
- emb_size (int):
Desired embedding width.
- num_nodes (int):
Number of nodes in the KG.
- seed (torch.Tensor, optional):
Seed used to generate random transformations (fully characterizes the embedder). Defaults to 42.
- device (Union[torch.device, str], optional):
PyTorch device to calculate embeddings on. Defaults to “cuda”.
- forward(node_features: Dict[int, Tuple[Tensor, Tensor]] | None = None, node_idx: Tensor | None = None) Tensor[source]
Encodes nodes into an initial (random) representation, with nodes with intial features (e.g. numeric literals) taken into account.
- Args:
- node_features (Dict[int, Tuple[torch.Tensor, torch.Tensor]], optional):
Dictionary with featured node type identifiers as keys, and tuples of node indices and initial features as values.
For example, if nodes [3, 5, 7] are literals of type 5 with numeric values [0.7, 0.1, 0.5], node_features should be: {5: (torch.tensor([3, 5, 7]), torch.tensor([0.7], [0.1], [0.5]))}
Featured nodes are not limited to numeric literals, e.g. word embeddings can also be passed for string literals.
The node indices used to specify the locations of literal nodes should be included in node_idx (if supplied).
If None, all nodes are assumed to be feature-less. Defaults to None.
- node_idx (torch.Tensor, optional):
Useful for batched embedding calculation. Mapping from node indices used in the given (sub)graph’s adjancency matrix to node indices in the original graph. Defaults to None.
- Returns:
torch.Tensor: Initial node representations
util
- rrgcn.util.calc_ppv(x: Tensor, adj_t: Tensor | SparseTensor) Tensor[source]
Calculates 1-hop proportion of positive values per representation dimension
- Args:
- x (torch.Tensor):
Input node representations.
- adj_t (torch.Tensor or torch_sparse.SparseTensor):
Adjacency matrix. Either in 2-row head/tail format or using a SparseTensor.
- Returns:
torch.Tensor: Proportion of positive values features.
- rrgcn.util.fan_out_normal_seed(shape: Tuple, device: device | str = 'cuda', seed: int = 42, dtype: dtype = torch.float32) Tensor[source]
Randomly generates a tensor based on a seed and normal initialization with std 1/fan_out.
- Args:
- shape (Tuple):
Desired shape of the tensor.
- device (torch.device or str, optional):
Device to generate tensor on. Defaults to “cuda”.
- seed (int, optional):
The seed. Defaults to 42.
- dtype (torch.dtype, optional):
Tensor type. Defaults to torch.float32.
- Returns:
torch.Tensor: The randomly generated tensor
- rrgcn.util.fan_out_uniform_seed(shape: Tuple, device: device | str = 'cuda', seed: int = 42, dtype: dtype = torch.float32) Tensor[source]
Randomly generates a tensor based on a seed and uniform initialization between -1/fan_out and 1/fan_out.
- Args:
- shape (Tuple):
Desired shape of the tensor.
- device (torch.device or str, optional):
Device to generate tensor on. Defaults to “cuda”.
- seed (int, optional):
The seed. Defaults to 42.
- dtype (torch.dtype, optional):
Tensor type. Defaults to torch.float32.
- Returns:
torch.Tensor: The randomly generated tensor
- rrgcn.util.glorot_seed(shape: Tuple, device: device | str = 'cuda', seed: int = 42, dtype: dtype = torch.float32) Tensor[source]
Randomly generates a tensor based on a seed and Glorot initialization.
- Args:
- shape (Tuple):
Desired shape of the tensor.
- device (torch.device or str, optional):
Device to generate tensor on. Defaults to “cuda”.
- seed (int, optional):
The seed. Defaults to 42.
- dtype (torch.dtype, optional):
Tensor type. Defaults to torch.float32.
- Returns:
torch.Tensor: The randomly generated tensor
- rrgcn.util.uniform_seed(shape: Tuple, device: device | str = 'cuda', seed: int = 42, dtype: dtype = torch.float32) Tensor[source]
Randomly generates a tensor based on a seed and uniform initialization.
- Args:
- shape (Tuple):
Desired shape of the tensor.
- device (torch.device or str, optional):
Device to generate tensor on. Defaults to “cuda”.
- seed (int, optional):
The seed. Defaults to 42.
- dtype (torch.dtype, optional):
Tensor type. Defaults to torch.float32.
- Returns:
torch.Tensor: The randomly generated tensor